강화학습을 이용한 응집제 주입률 최적화 | DBpia
박종률, 허환, 서정수, 김태진, 심민규, 강문숙 | 대한전자공학회 학술대회 | 2022.6
www.dbpia.co.kr
서론
y: 적정 응집제 주입률(dosage rate)
x: 유입 원수 의 탁도(Turbidity, TB), pH, 알칼리도(Alkalinity, Alk) 등의 수질인자
침전 공정이 끝난 침 전수의 탁도(Turbidity of Sedimentation Basin, TBS) 를 통해 적정한 응집제 주입률을 측정
환경부 정수처리기준:
-여과시설 탁도기준
매월 채취된 시료수의 95% 이상이 0.3NTU이하, 각 시료의 측정값을 1.0NTU이하
여과 공정 직전에 측정되는 침전수 탁도: 일반적으로 1.0NTU이하, 평균 0.5NTU이하
다양한 정수장에 해당 방법을 적용할 경우 각 정수장별 데이터 특성을 고려해야하기 때문에 정수장 별로 모델을 개발해야 하는 높은 비용 문제가 발생할 수 있다
연구 목적: 수질 기준을 충족하면서 최소한의 약품을 투입하 는 경제적 학습 조건을 기반으로 강화학습을 이용한 응집제 주입률 최적화 모델을 제안하고자 한다.
본론
데이터
연구에서 사용된 데이터
-정수장 착수정으로 유입되는 원수에서 시료를 채취하여 Jar-Test를 수행한 실험 데이터
-2011년부터 약 10년 간 비정기적으로 수집된 데이터
-동일 원수에 대해 응집제를 주입한 뒤, 약 30분 후의 침전수 탁도를 기록
-원수 수질 변수: 탁도, pH, 알칼리도
-조절변수: 응집제 주입률
시뮬레이터: 의사결정나무, max_depth=10

마코브 의사 결정 과정
-이산확률과정(Discrete Time Stochastic Process)에서 최적의 의사결정을 내리는 수학적 프레임워크를 제공
-4-튜플 (S, A, P, R)로 정의된다. 여기에서 S는 상태, A는 행동, P 는 상태 간의 전이확률 프로세스, R은 보상을 의미
-S(상태): 원수의 탁도(2~20NTU, 95%이상) --> 연구에서는 해당구간의 원수 탁도를 로그변환 사용
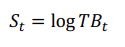
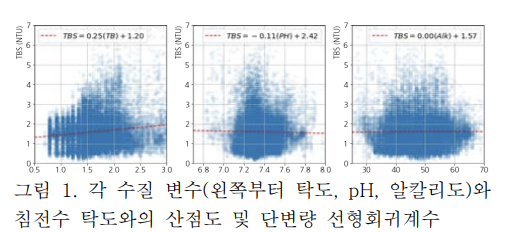
원수 탁도와 침전수 탁도의 비선형적인 관계를 보다 명확하게 식별하기위해 3차원 벡터로 구성

-A(행동): 원수 탁도 분석 구간 에서 테스트한 응집제 주입률의 범위(4.5~20ppm)을 로그변환

-P(전이확률): 하나의 타임스텝을 30분으로 하여 아래와 같은 이산 확률 과정이 정의

**함수 f 는 앞서 설계한 시뮬레이터(시뮬레이터: 의사결정나무, max_depth=10이며 닫혀있는 시스템에서의 응집 침전 프로세스, 입력: 탁도와 주입률 입력값, 출력: 침전수 탁도 예측값)
강화학습은 환경을 모두 파악할 수 있을떄 사용한다 ==> 환경을 가정하였다.
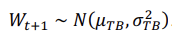
-닫혀있는 시스템의 효과: a(알파)
-열려있는 시스템의 효과: 1-a(알파)의 비중으로 원수의 탁도를 결정한다
-a(알파): 를 0.5로 정의했음
-R(보상): 응집제 주입의 목적은 침전수 탁도를 낮추는 것임과 동시에 응집제 주입률을 과도하게 설정하지 않는 것

*I: 지사함수, 처리된 물 농도가 2NTU 초과 --> 패널티
------
각 원수 상태에서 침전수 탁도가 목표 침전수 착도 값을 충족하면서 응집제 주입률이 최소가 되는 경계에서 에이전트 행동이 채택된다
'2023 > 물사랑 나라사랑' 카테고리의 다른 글
| 최종데이터 처리 (0) | 2023.09.24 |
|---|---|
| 머신러닝 모델위주 (0) | 2023.09.11 |
| EDA 정리 (0) | 2023.09.08 |
| 연습 데이터) 상수원-취수원 통합 수질 및 녹조 데이터 (0) | 2023.09.07 |
| 요약) 응집제의 염기도가 응집에 미치는 영향 (0) | 2023.09.05 |