728x90
반응형
목적 : 스위스에서 주로 사용하는 고객을 위해 NER을 수행한다
데이터셋
- 'PAX-X' 라고 불리는 교차 언어 전이 평가(Cross-Lingual TRansfer Eveluation of Multilingual Encoders, XTREME)을 사용
- 스위스에서 사용되는 4개의 언어(독일어, 프랑스어, 이탈리아어, 영어)를 비율을 조정하여 데이터셋 구성
- 각 언어에 대해서 IOB2포맷(개체에 해당되는 첫 토큰은 B-로 시작하고 연속되는 토큰은 I-로 표시, 아무것도 속하지 않으면 O 료시) 의 NER 태그가 표시되어있다
- NER 태그
B- : 개체명 시작
0 : 어떤 개체에도 속하지 않는다
I- : 개체명 연속
- NER 태그
- 개체명의 종류 : LOC, PER, ORG
from datasets import get_dataset_config_names
xtreme_subsets = get_dataset_config_names("xtreme")
print(f"XTREME 서브셋 개수: {len(xtreme_subsets)}") # output:XTREME 서브셋 개수: 183
panx_subsets = [s for s in xtreme_subsets if s.startswith("PAN")] # 'PAN-X'를 사용하기 위해 PAN으로 시작하는 서브셋 리스트에 저장
panx_subsets[:3] #서브셋 3개의 이름 확인 (['PAN-X.af', 'PAN-X.ar', 'PAN-X.bg'])
말뭉치 샘플링
from collections import defaultdict
from datasets import DatasetDict
langs = ["de", "fr", "it", "en"] # de 독일, fr 프랑스, it 이탈리아, en 영어
fracs = [0.629, 0.229, 0.084, 0.059] # 언어별 데이터 구성 비율 지정
# 키가 없는 경우 DatasetDict로 초기화
panx_ch = defaultdict(DatasetDict)
for lang, frac in zip(langs, fracs): # zip
ds = load_dataset("xtreme", name=f"PAN-X.{lang}") #다국어 말뭉치 로드
for split in ds: # ds는 train, test, validation을 키로 갖는 딕셔너리
# seed = 0으로 하여 랜덤하게 섞고 지정해둔 비율 만큼의 데이터의 인덱스를 랜덤하게 선택
# panx_ch에 추가
panx_ch[lang][split] = (
ds[split]
.shuffle(seed=0)
.select(range(int(frac * ds[split].num_rows))))
* defaultdict
- from collections import defaultdict
- 일반적인 dict는 키와 값을 추가한 후 해당 키에 접근할 수 있음 하지만 defaultdict는 존재하지 않는 키에 접근하여 그 값을 수정할 수 있음
- defaultdict()에 초기값을 지정하면 키값이 없어도 해당 초기값에 대해서 조작이 가능하다

* ds
- lang별 DatasetDict, train/test/validation을 키로한다
- for split in ds를 적용하면 ds의 키인 train/test/validation의 값을 순회한다

샘플링한 데이터 언어별 갯수 확인
- df(독일), fr(프랑스), it(이탈리아), en(영어)
import pandas as pd
pd.DataFrame({lang: [panx_ch[lang]["train"].num_rows] for lang in langs},
index=["Number of training examples"])
- 지정한 비율만큼의 개수를 각 언어별로 랜덤하게 뽑았다
* panx_ch의 샘플 확인
- Sequence() : 특성 리스트를 담고 있음을 의미한다 (iterable, len(), index)
- feature : 시퀀스의 각 타입 요소를 정의
- length : 시퀀스의 길이를 정의, -1은 시퀀스 길이가 고정되지 않아 가변적이라는 것을 의미
- id : 시퀀스 고유 식별자를 정의
- token, ner_tags, langs를 키로한다

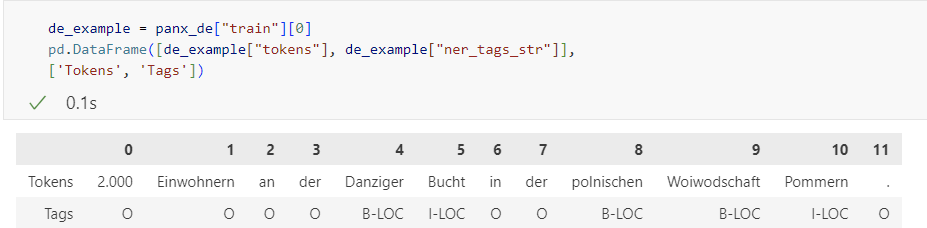
* panx_ch의 독일어 말뭉치의 0번 인덱스를 예시로 확인

* 'ner_tags' -> 해당 인덱스에 해당하는 ner_tag로 변환
# 독일어의 train에 해당하는 class label을 tags에 저장
# ClassLabel(names=['O', 'B-PER', 'I-PER', 'B-ORG', 'I-ORG', 'B-LOC', 'I-LOC'], id=None)
tags = panx_ch["de"]["train"].features["ner_tags"].feature
# 인덱스 -> 텍스트
def create_tag_names(batch):
# 'ner_tags'를 하나씩 순회하면서 대응되는 index에 해당하는 ner_tag label을 저장
return {"ner_tags_str": [tags.int2str(idx) for idx in batch["ner_tags"]]}
# 적용할 데이터.map(적용할 함수)
panx_de = panx_ch["de"].map(create_tag_names)
** 문자인 토큰과 태그를 df형식으로 변환해서 확인
다중 언어 트랜스포머
- 훈련에 사용된 언어 이외의 다른 언어를 투입해도 단일언어 모델과 비슷한 성과를 낸다
- 언어에 대한 내부 특성을 학습하는것이니 말이 된다잉
다중 언어 트랜스포머 모델 훈련 방식
- en : 다국어로 사전훈련된 모델을 영어 훈련 데이터로 미세튜닝 후 대상 언어로 평가
- each : 다국어로 사전훈련된 모델을 하나의 대상 언어로 미세튜닝 한 후 평가
- all : 대국어로 사전 훈련된 모델을 여러개의 언어에 대해 미세튜닝 후 평가
XLM-R
- 사전 훈련 목표로 100개의 언어에 대한 MLM만 사용 -> 다중언어 처리 가능
- XLM의 다음 문장 예측 작업을 제거하여 BERT의 성능을 높힘
- XLM의 임베딩 제거, SentencePiece를 사요하여 원시 텍스트를 직접 토큰화
- XLM-R의 어휘사전의 크기가 크다(RoBERTa 55000, XLM-R 250000)
XLM-R 토큰화
- 100개의 언어에서 훈련된 SentencePiece토크나이저를 사용한다
- BERT 토크나이저와는 토크나이징 되는 형태가 다르다
WordPiece vs SentencePiece
- WordPiece
- BERT모델을 사전 학습 시키기 위해 Google에서 개발한 토큰화 알고리즘
- 가장 작은 단위로 텍스트를 쪼개 쌍의 빈도를 각 부분의 빈도의 곱으로 나누어 어휘에서 개별 부분의 빈도가 낮은 쌍의 병합에 우선순위를 둔다
- score=(freq_of_pair)/(freq_of_first_element×freq_of_second_element)
- SentencePiece
- 각 입력 텍스트를 유니코드 문자 시퀀스로 인코딩
- 사전 토큰화 작업 없이 토큰화를 진행하여 언어의 종에 종속적이지 않다
- 공백을 보존한다
from transformers import AutoTokenizer
bert_model_name = "bert-base-cased" # WordPiece tokenizer
xlmr_model_name = "xlm-roberta-base" # SentencePiece toknizer
bert_tokenizer = AutoTokenizer.from_pretrained(bert_model_name)
xlmr_tokenizer = AutoTokenizer.from_pretrained(xlmr_model_name)
text = "Jack Sparrow loves New York!"
bert_tokens = bert_tokenizer(text).tokens()
xlmr_tokens = xlmr_tokenizer(text).tokens()
df = pd.DataFrame([bert_tokens, xlmr_tokens], index=["BERT", "XLM-R"])
df
* 토큰화 결과 비교

토큰화 파이프라인
- 정규화 : 원시 문자열을 깨끗하게 만든다 (공백, 악센트 제거, 대소문자 통합)
- 사전 토큰화 : 텍스트를 더 작은 객체로 분할한다 (공배ㄱ, 구두점을 기준으로 분할)
- 토크나이저 모델 : 정규화와 사전 토큰화를 진행 후 토크나이저 모델(사전훈련모델을 사용할 수 있으며 그렇지 않으면 직접 학습이 필요하다)을 사용하여 부분단어로, 문자형이 아닌 정수(입력id) 리스트를 가진다
- 사후처리 : 토큰 리스트 (정수의 값이 들어있음)에 부가적인 변환을 적용(문장구분, 문장 분할 토큰을 추가한다)
SentencePiece토크나이저
- 유니그램을 기반으로 각 입력 텍스트를 유니코드 문자 시퀀스로 인코딩
- 악센트, 구두점에 대해서 몰라도 된다
- 다국어 말뭉치에 유용
- 공백 문자가 우니코드 기호 U+2581 또는 _ 문자에 할당된다 (공백을 보존) -> 언어별 사전 토크나이저에 의존적이지 않고 정확하게 시퀀스를 복원한다
NER 트랜스포머
- 입력텍스트 -> 토큰화 -> 인코더 -> 히든스태이트 -> feedforward -> 출력 tag
- 하나의 태그 내에서 토큰화로 나눠져서 모델에 투입되면 출력시에는 앞서오는 토큰에 대해서 레이블을 할당하고 뒤따라오는 토큰의 태그는 IGN로 표시한다
트랜스포머를 용도에 맞추어 수정
- 모델의 마지막 층이 후속 작업에 맞는 층으로 바뀐다
- 헤드 : 모델의 마지막 층
- 바디 : 헤드를 제외한 층
- 사용자가 헤드를 정의하여 작업에 맞는 모델로 변형할 수 있다
- 헤드 정의
- feedfrward() 함수로 초기화 설정할 객체와 출력을 생성한다
- 여기에서는 NER태그를 분류하는거니까 마지막 nn.Linear의 출력 노드는 NER태그의 개수가 된다a
import torch.nn as nn
from transformers import XLMRobertaConfig
from transformers.modeling_outputs import TokenClassifierOutput
from transformers.models.roberta.modeling_roberta import RobertaModel
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel
class XLMRobertaForTokenClassification(RobertaPreTrainedModel): # RobertaPreTrainedModel class 상속
config_class = XLMRobertaConfig
def __init__(self, config):
super().__init__(config)
# 레이블 지정
self.num_labels = config.num_labels
# 모델 바디를 로드합니다.
self.roberta = RobertaModel(config, add_pooling_layer=False)
# 토큰 분류 헤드를 준비합니다.
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.classifier = nn.Linear(config.hidden_size, config.num_labels)
# 가중치를 로드하고 초기화합니다. -> 헤드 부분의 가중치(바디의 가중치는 이미 존재함)
self.init_weights()
def forward(self, input_ids=None, attention_mask=None, token_type_ids=None,
labels=None, **kwargs):
# 모델 바디를 사용해 인코더 표현을 얻습니다.
outputs = self.roberta(input_ids, attention_mask=attention_mask,
token_type_ids=token_type_ids, **kwargs)
# 인코더 표현을 헤드에 통과시킵니다.
sequence_output = self.dropout(outputs[0]) # outpurs[0] 바디의 은닉층을 헤드에서 입력으로 받아서 dropout
logits = self.classifier(sequence_output) #
# 손실을 계산합니다.
loss = None # 손실 초기화
if labels is not None:
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
# 모델 출력 객체를 반환합니다.
return TokenClassifierOutput(loss=loss, logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions)
AutoConfig
- from_pretrained()에 클래스 이름이나 갯수 등을 커스터마징
from transformers import AutoConfig
# 사용자 지정을 사용하기 위해 변수 정의
index2tag = {idx: tag for idx, tag in enumerate(tags.names)}
tag2index = {tag: idx for idx, tag in enumerate(tags.names)}
xlmr_config = AutoConfig.from_pretrained(xlmr_model_name,
num_labels=tags.num_classes, # 클래스의 개수를 재정의한다
id2label=index2tag, label2id=tag2index) #id2label, label2id를 위에서 정해놓은 방법대로
NER작업을 위한 텍스트 토큰화
- 리스트로 단어와 태그를 준비한다
- 각 단어를 토큰화한다
- word_ids() : 토큰에 id를 부여, 부분단어 마스킹(같은 단어에서 나누어져 토큰화된 것에 대해 같은 단어였다는 것을 표시)
- 특수토큰과 부분 단어에 대해 -100으로 마스킹한다 (-100인 이유는 nn.CrossEntropy의 ignore_index가 -100임)
def tokenize_and_align_labels(examples):
tokenized_inputs = xlmr_tokenizer(examples["tokens"], truncation=True,
is_split_into_words=True)
labels = []
for idx, label in enumerate(examples["ner_tags"]):
word_ids = tokenized_inputs.word_ids(batch_index=idx) #idx로 input에 대해 word id를 부여
previous_word_idx = None
label_ids = []
for word_idx in word_ids:
if word_idx is None or word_idx == previous_word_idx:
# word idx==None : <s>, </s> 같은 특수 토큰
# word_idx == previous_word_idx : 한 단어에서 갈라진 경우 앞선 토큰만 고려한다
label_ids.append(-100) # -100은 무시한다는 의미
else:
label_ids.append(label[word_idx]) # 토큰의 word_idx 인덱스에 해당하는 정수를 반환
previous_word_idx = word_idx
labels.append(label_ids)
tokenized_inputs["labels"] = labels
return tokenized_inputs# 분할에 대해 반복 수행
def encode_panx_dataset(corpus):
return corpus.map(tokenize_and_align_labels, batched=True,
remove_columns=['langs', 'ner_tags', 'tokens'])
성능지표
- swqeval 의 classification_report를 사용하여 분류 결과를 확인
- 이중 리스트로 구성된 레아블을 입력 받기 때문에 예측도니 레이블을 이중 리스트 형식으로 변환해야한다.
XLM-RoBERTa 미세튜닝하기
- TrainingArguments클래스를 사용하여 훈련 속성을 정의한다
- 평가지표를 계산 가능한 형태로 만든다(이중 리스트)
- DataCollcatorForTokenClassification : 토큰분류를 이한 입력과 레이블을 패딩하는 전용 데이터 콜레이터
- model_init 함수를 사용하여 모델 초기화 함수를 생성
- Trainer에 인코딩된 데이터세소가 함께 모든 정보를 전달한다
- 훈련루프 실행 -> 훈련 -> huggingface hub에 모소델을 업로드
오류분석
- 모델이 잘 작동하는것 같이 보이지만 내면은 그렇지 않을수도
- 우연히 너무 많은 토큰을 마스킹하고 일부 레이블도 마스킹하여 제대로 훈련되는것 처럼 보이는 경우
- compute_metrics()에 실제 성능을 과대평가하는 버그가 있음
- NER에 0 클래스 또는 0개체명이 일반 클래스 처럼 포함되는 경우가 있음 -> 0을 일반 레이블로 예측하는 경우 0 클래스는 압도적인 다수 클래스 -> 평가지표의 점수가 왜곡된다
- 손실이 가장 큰 검증 샘플을 살펴본다 -> 샘플의 시퀀스마다손실을 계산
- 각 샘플의 토큰, 레이블, 예측 레이블 들을 담은 리스트를 살펴본다 -> 입력 토큰을 기준으로 토큰의 개수, 토큰 손실의 평균과 합 계산이 가능 => 검증셋에서 누적 손실이 가장 큰 토큰을 찾을 수 있음
- 레이블 id로 묶어서 태그별로 손실의 합, 평균, 등장 빈도를 확인할 수 있음
- 라벨링의 문제
- 실버 스탠다드의 등장 PAN-X데이터셋의 레이블이 자동으로 생성된것 (사람이 라벨링한것 : 골드 스탠다드)
- => 간단한 분석으로 모델과 데이터의 약점을 분석하여 찾아내고 개선하는 것을 반복하여 목표 성능에 도달
교차 언어 전이
- 여러 언어로 사전 훈련된 모뎅 -> 특정 언어(예:독일어)에 대해 미세튜닝 -> 미세튜닝하지 않은 언어(예: 프랑스어)를 투입 => 결과가 나쁘지 않음(단일 언어로 미세튜닝된 모델과 비교해보면 그 차이를 확인이 가능하며 결과가 나쁘게 나오는 경우도 있다)
제로샷 전이가 유용한 경우
- 단일언어 말뭉치 미세튜닝한 것과 제로샷 전이를 비교한다
- XLM-R모델에 단일언어 말뭉치를 증가시키면서 미세튜닝을 한다
- 몇개의 데이테를 학습시켜야 교차 언어 전이를 수행하는것보다 나은 결과를 내는지를 구한다 (이 과정은 단일언어 미세튜닝하는 경우 몇개의 데이터를 더 수집해야하는지를 알 수 있음)
- 예를들어 약 750개일 때까지 제로샛 전이가 앞서고 그 이후에는 미세튜닝이 앞선다면 미세튜닝의 효과를 내려면 최소 750개의 데이터가 더 필요하다는 의미 => 미세튜닝시 필요한 데이터 수집과 데이터 전처리, 라벨링 과정을 줄일 수 있음
다국어에서 동시에 미세튜닝
- 다국어 데이터셋을 모두 concatenate -> 모델을 미세튜닝
- 다국어 데이터셋에 포함되지 않은 언어에 대해서도 성능이 향상된다
결론
- 교차 언어 전이는 미세튜닝에 사용할 데이터가 적을 경우 유용하다
- 교차 언어 전이는 훈련시 포함된 언어가 아니라면 그 성능은 그리 좋지 못하다
- 최근 연구에서 MAD-X가 들장하였음. 이는 데이터가 부족한 상황을 위해 설계가 되었으며 트랜스포머 위에 구축되었다
728x90
반응형
'Deep Learning > 트랜스포머를 활용한 자연어 처리' 카테고리의 다른 글
| [chapter 6] 요약 (0) | 2024.06.22 |
|---|---|
| [Chapter 5] 텍스트 생성 (0) | 2024.06.19 |
| [Chapter 3] 트랜스포머 (0) | 2024.05.22 |
| [Chapter 3] 코드_1 (0) | 2024.05.17 |