import pandas as pd
df = pd.read_csv('file path', index_col=0)
DataFrame의 특정 Series에 접근
data frame object의 attribute로 접근하는 방법
1)
# df의 attribute로 접근
df.feature1만약 col들 중 그 이름에 띄어 쓰기가 포함 되어 있는 경우는 이 방법을 사용하지 못하고 이런 경우에는 2) 방법을 사용하여야한다
2)
# 딕셔너리에 접근하는 방법처럼 indexing operator([])을 사용하여 접근
df['feature1']
두개의 방법 모두 같은 결과를 출력한다.

해당 Series의 개별 원소에 접근하는 방법 -> indexing operator ([]) 을 사용한다
df['feature1'][0]
Indexing
- pandas는 인덱스 접근을 위해 .iloc, .loc operation을 제공한다
- indexing operator : [], slicing operator : ' : '
Index based selection (iloc)
- data frame의 정수 인덱스를 기반으로 검색
df.iloc[0]df의 0번째 index에 해당하는 row 값들이 출력된다.
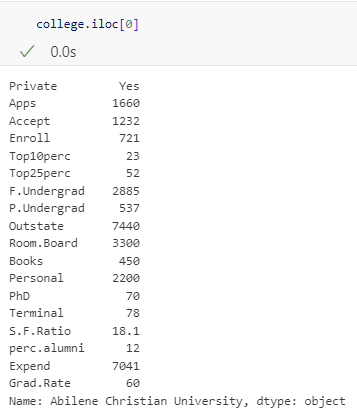
** iloc의 indexing operator 배치 순서 -> [row, column]
df.iloc[:,0] # 전체 행, 0번째 인덱스에 해당하는 결과를 출력
** : -> 전체를 의미함 (예: df[:3, 0] -> 처음~2번째 인덱스 행과 0번째 열을 출력한다)

연속적인 인덱스 뿐만 아니라 떨어져 있는 인덱스의 값도 지정 가능
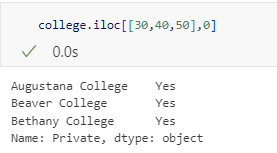
** 음수 indexing/slicing**
- 음수 : 역방향으로 진행된다
- df의 가장 마지막 row에 접근하기 위해서는 df.iloc[-1]을 하면 마지막 행에 접근 가능하다
- ( if df.shape == (5, 2) ) df.iloc[5] == df.iloc[-1]
Label based selection (loc)
- 지정한 행, 열의 label로 조회한다 (만약 행, 열의 이름을 숫자로 지정했다면 정수 iloc과 같이사용할 수 있지만 행, 열의 이름을 문자로지정했다면 조회할 때도 문자로 조회해야한다)
- 'college' data frame의 인덱스가 대학교의 이름으로 지정되어 있다면 행을 조회할 때 대학교의 이름으로 인덱싱을 진행해야한다
# 슬라이싱도 label로 가능하다 -> df.loc[:'col_name', 'row_name']
# 여러개의 열 -> df.loc[:'col_name', ['row_name_1':'row_name_4']]
# -> df.loc[:'col_name', ['row_name_1','row_name_3','row_name_4']]
df.loc['col_name', 'row_name']
예시)
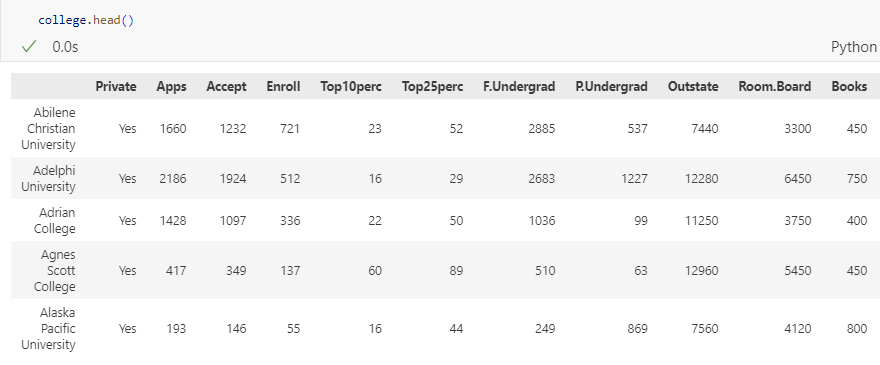
- 행 : 대학교 이름 (문자형) / 열 : 문자형

** 근데 만약 행이 unique하지 않다면?

연속적인 non-unique행을 조회하면 가장 마지막 행에 대해서 인덱싱을 수행한다. 근데 떨어져있는 것도 될까? 해서 해봤더니 안된다. 왜그런지는 잘모르겠지만 연속적이면 가능하고 떨어져 있으면 KeyError가 난다. 하지만 대부분 index열은 unique한 값을 가지는 열을 지정하니까 크게 문제가 되지 않을것이다.

loc vs iloc
iloc
- 정수 인덱스로 접근한다
- 슬라이싱 할 때 [1:10,:]이라면 1번 idx ~ 9번 idx에 해당하는 열을 반환한다 (python의 기본 체계와 같음)
loc
- 지정한 행, 열의 이름으로 접근한다
- 슬라이싱 할 [1:10,:]이라면 1번 idx ~ 10번 idx에 해당하는 열을 반환한다 (총 선택된 row의 수가 iloc보다 1 많음)
Manipulating the index
- index열을 변경할 수 있다
df.set_index('col_1')
Conditional selection
- 조건에 부합하는 정보를 찾는다
- 조건에 부합하면 True, 그렇지 않으면 False이고 True에 해당하는 값을 확인할 수 있다.
- and(&), or(|) 등의 연산 가능
- 숫자 : 부등호 (비교연산)
- 문자 : ==, !=
df.col_name1 == 'data'
# df.loc[df.col_name1 == 'data']# and
df.loc[(df.col_name1 == 'data1') & (df.col_name2 == 'data2')]
# or
df.loc[(df.col_name1 == 'data1') | (df.col_name2 == 'data2')]
isin() : 해당 column에서 isin의 대상이 있는 것만 추출 (col_name1 열에서 data1, data2와 같은 행만 추출한다)
df.loc[df.col_name1.isin(['data1','data2'])]
isnull(), notnull() : 선택한 열의 값이 null/not null인 행을 추출
# null인것만
df.loc[df.col_name1.null()]
# null이 아닌것만
df.loc[df.col_name1.notnull()]
Assigning data
- 선택한 열에 값을 채워넣기
- 하나씩 or 한번에 모두 가능함
df['col_name1'] = 'A' # 해당 컬럼의 모든 값이 A로 바뀐다
df['col_name1'] = range(len(reviews), 0, -1)) #해당 컬럼의 값이 df(len)에서 하나씩 중러들면서 열이 채워진다'Python > Pandas' 카테고리의 다른 글
| [kaggle learn pandas] Data Types and Missing Values (0) | 2024.05.30 |
|---|---|
| [kaggle learn pandas] Grouping and Sorting (0) | 2024.05.30 |
| [kaggle learn pandas] Summary Functions and Maps (0) | 2024.05.27 |
| [kaggle learn pandas] Creating, Reading and Writing (0) | 2024.05.27 |
| pandas 자주 사용하는 기능(물론 내가) (0) | 2023.11.29 |