**참고 Gareth James, Daniela Witten, Trevor Hastie, Robert Tibshirani. An Introduction to Statistical Learning : with Applications in R. New York :Springer, 2013.
분류 (Classification)
질적 반응변수(qualitative variable, categorical)인 경우 (양적 반응변수(quantitative variable)인 경우는 선형회귀)
각 클래스에 대한 확률 계산 -> 가장 확률 높은 클래스로 분류 하는 과정
선형회귀로 분류 => 효과적이지 않음
선형회귀로 분류문제를 모델링하는것은 적절하지 않다.
이진분류의 경우
dummy variable로 변형하여 선형회귀 모델링이 가능하지만 Yhat이 확률의 범위를 벗어남
확률의 범위 : [0,1] -> binary 선형회귀모델 적용 : [-inf, +inf] => 확률적으로 해석 어려움
3개 이상의 클래스 분류의 경우
dummy variable로 만들경우 각 class의 차이가 동일하다는 의미를 가질 위험이 있음
세가지 class가 독립적이만 잘못된 의미를 가져 검정 관측치들을 제대로 분류할 수 없음
3개 이상의 질적 변수를 양적 변수로 변환하는 자연스러운 방법은 없음
로지스틱 회귀 (Logistic Regression)
주어진 설명변수 X에 대해 반응변수 Y의 조건부 분포(Pr(Y=k|X=x))를 직접 모델링한다
반응변수 Y를 선형회귀처럼 직접 모델링하지 않고 확률을 먼저 구하고 최대 확률을 가지는 클래스로 분류
(확률을 구한다) 선형회귀와 다르게 Yhat의 범위가 [0,1]로 확률 범위와 동일함
(클래스에 할당한다) p(X) > 0.5 -> class 1, else -> class 0 => 0.5는 임계치로 조정 가능함
단순 로지스틱 모델 (설명변수 X = 1개)
모든 X값에 대해서 [0,1]의 값을 제공한다
모델 적합 : 최대가능도 추정 (Maximum Likelihood Estimation) 이 최대인 β0, β1을 찾는다
로지스틱 모델의 식의 확장 : 오즈 (odds)
A 사건이 일어날 확률을 p라고할 때, A 사건이 일어날 승산(odds)
비율의 의미를 담고 있음
로짓 (logit, log-odds)
로지스틱 회귀 모델은 X에 선형적인 로짓을 갖는다
입력변수의 선형 결합을 확률로 변환 -> 이진분류 문제 해결
X 한 유닛의 증가 => 오즈에 e^( β1)을 곱하는 것과 같음 (하지만 p(X)는 X의 현재값에 따라서 다름)
β1이 음수 -> X증가는 p(X)감소와 연관
β1이 양수 -> X증가는 p(X)증가와 연관
회귀계수의 추정
최대가능도 추정 (MLE)가 최대일때의 파라미터( β0,β1 )를 찾는다
*다중 로지스틱회귀 (설명변수 X의 > 2개 이상)
단순 로지스틱 회귀에서 X와 파라미터를 추가 => 나머지는 단순 로지스틱 회귀와 동일
다중로지스틱 회귀 식
다중 로지스틱 회귀 logit
다중 로지스틱 회귀의 경우 설명변수 끼리 상관성이 있는 경우가 있음 => 이 경우 단순 로지스틱 회귀로 모델링하면 다중 로지스틱회귀의 결과와 많이 다를 수 있음 (교락, confounding)
반응변수의 클래스가 2개보다 많은 경우 (p > 2)
로지스틱 회귀를 확장할 수는 있지만 판별분석 (Discriminant Analysis) 방법을 사용한다
베이즈 정리
식에 쓰인 항들의 값이 모두 올바르게 명시되는 경우에만 사용 가능 => 일상생활에서 사용 불가
분류기 중 오차가 가장 낮다
밀도함수를 추정할 수 있다면 베이즈 분류기에 근접하는 분류기 추정 가능
선형판별분석 (Linear Discriminant Analysis)
반응변수 Y의 각 클래스에서 설명변수 X의 분포를 모델링하고 베이즈 정리를 이용하여 Pr(Y=k|X=x)에 대한 추정치를 얻는다
p = 1
fk(x)를 추정하기 위해서
fk(x)는 정규분포(가우스 분포)이다
모든 k개의 클래스는 공통분산을 가진다
LDA는 마지막 식을 최대로 하는 클래스에 관측치를 할당한다
마지막 식이 x에 대한 일차식임 -> 선형인 이
베이즈 분류기는 마지막 식을 최대로 하는 클래스에 관측치를 할당하는 것과 동일함
파라미터 추정
각 클래스별 평균, 랜덤하게 클래스에 속할 확률, 분산을 추정해야한다.
p > 1
p=1인 경우와 동일한 과정을 수행 (파라미터 추정, 마지막 함수 최대인 클래스로 할당)
오차율이 낮은 경우 주목해야 할 점
과대적합 : n < p 이면 과대적합을 의심해봐야한다
영분류기(null classifier)로 분류하는 경우의 오차율과 큰 차이가 있는지 확인
임계치 변경 trade-off
검정 : 전체 오류율, 파랑 : FP, 주황 : FN
FP(파랑)를 줄이는게 목표라면 임계치는 작아질 수록 FP가 작아지지만 전체 에러율은 임계치가 낮을 때 높음
이런 경우 어떤 임계치가 가장 적절한지 도메인 지식을 기반으로 임계치 설정이 필요함
분류기의 성능 평가 -> ROC curve
ROC곡선의 아래 면적(AUC)이 커질수록 좋은 분류기임
TP의 비율이 높고, FP의 비율이 낮을 수록 좋은 모델 (== AUC가 큰 경우)
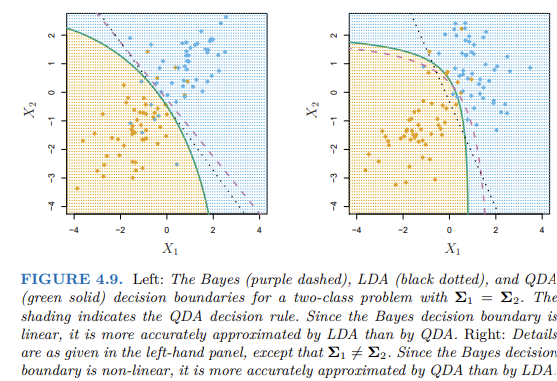
이차선형판별분석 (QDA, Quadratic Discriminant Analysis)
각 클래스가 자체 공분산을 가진다고 가정
VS LDA
QDA가 더 유연한 모델임
훈련 관측데이터의 수가 작다면 -> LDA => 분산을 줄이기 위해
훈련 관측데이터의 수가 많고 K개의 클래스들이 공통의 공분산 행렬을 갖는다는 가정이 명백히 맞지 않다면 -> QDA를 사용
- 모든 클래스가 공분산 행렬을 가지는 경우 -> lda의 결정경계가 베이즈와 유사하다 - 각 클래스가 다른 공분산을 가지는 경우 -> QDA의 결정경계가 베이즈와 유사하다